Voilà quinze ans que Photoshop a commencé à tirer parti des architectures multiprocesseurs. Le responsable technique de Photoshop chez Adobe répond aux question d'un ingénieur d'Intel : quelles perspectives de progression reste-t-il alors qu'on approche du plafond prédit par la loi d'Amdahl ?
Avec l'avènement des machines multiprocesseurs, on parle de plus en plus de calcul parallèle : le découpage d'une tâche en plusieurs afin de les exécuter simultanément sur plusieurs processeurs, pour tirer le meilleur parti du matériel.
Si Snow Leopard a mis l'exécution de code en parallèle sur le devant de la scène, avec Grand Central Dispatch et OpenCL, cette technique est pourtant assez ancienne. Elle était particulièrement mise à profit sur les serveurs (chaque tâche étant lancée par un client distinct, la mise en parallèle du code était relativement aisée). Cette architecture s'est retrouvée au sein de l'ordinateur de Monsieur Tout-le-Monde lorsque les fabricants de processeurs sont arrivés au bout de la course au mégahertz : l'augmentation de la cadence des processeurs devenait trop coûteuse et consommatrice d'énergie pour continuer à se justifier.
Mais dans le monde Mac, les machines multiprocesseurs remontent bien avant l'arrivée des processeurs Intel dans nos machines.

En 1995, Apple lancera le Power Macintosh 9500 dont un modèle inclut deux processeurs PowerPC cadencés à 180 MHz, succédé par le Power Macintosh 9600 équipé de deux processeurs à 200 MHz. En 1997, alors qu'Apple avait signé des accords de licence permettant à des constructeurs de fabriquer et vendre des machines compatibles avec Mac OS 8, la société Daystar avait mis sur le marché le Genesis MP, un "monstre" de puissance qui dépassait tout ce qui se faisait de mieux en Mac, à l'aide de quatre processeurs PowerPC 604e cadencés à 225 MHz. Plusieurs configurations de Power Mac G4 et G5 proposeront deux processeurs, le Power Mac G5 sera même équipé en bi-processeurs bi-cœurs en 2006.
Mais si les logiciels ont pu bénéficier de l'augmentation de la fréquence d'horloge des processeurs de manière automatique, sans avoir à être modifiés ou recompilés, les machines multiprocesseurs ne pouvaient être pleinement mises à profit qu'en modifiant les applications spécifiquement. Et en 1995, il n'y avait pas l'ombre d'un Mac OS X en vue, sans même parler de Grand Central Dispatch. Les développeurs étaient donc livrés à eux-mêmes pour tirer parti de ces monstres de puissance.
Un processeur surnuméraire qui ne fait qu'acte de présence
En conséquence, à l'époque bien peu nombreuses sont les applications qui ont été réécrites pour exploiter plus d'un processeur à la fois. Mais s'il est une application, entre toutes, qui peut gagner beaucoup à cette conversion, c'est bien Photoshop, avec ses calculs gourmands en puissance, d'autant plus que le calcul graphique se prête particulièrement bien au calcul parallèle. En effet, à son niveau le plus simple il suffit de diviser l'image sur laquelle on applique un filtre pour en distribuer chaque morceau à traiter par un processeur. Le logiciel à lui seul justifie l'achat de ces machines hors de prix : c'est d'ailleurs une chance, car peu d'autres applications exploitaient à l'époque plus d'un processeur. Photoshop est en conséquence un vétéran du calcul parallèle.
Mais à l'heure où les configurations octo-core, voire hexadéca-core (!) poignent à l'horizon, de nouveaux défis se profilent pour le logiciel d'édition graphique. Car ça n'est pas le tout de convertir certaines parties du code pour les adapter au calcul parallèle : à mesure de l'augmentation du nombre de processeurs, il faut proportionnellement augmenter le pourcentage de calcul parallèle pour continuer à en tirer des bénéfices sensibles. C'est un des enseignements de la loi d'Amdahl, du nom de l'ingénieur d'IBM qui l'a édictée.
Le plafond d'Amdahl
Et précisément, un code rendu parallèle à 50 % ne présentera plus d'accélération sensible entre 8 et 16 processeurs, comme établi sur le schéma ci-dessous.
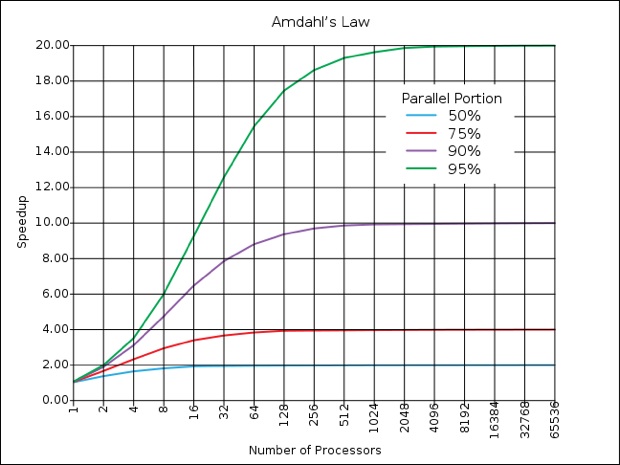
Pour continuer à sentir la moindre accélération à chaque multiplication de processeurs, il faut donc convertir au parallélisme une partie de plus en plus importante du code, faute de quoi cette multiplication se fait en pure perte. Pour compliquer encore les choses, la multiplication des processeurs peut provoquer quelques congestions au niveau de l'accès à la mémoire vive, qui est partagée avec chacun d'entre eux : plus il y a de processeurs qui provoquent des lectures et écritures en mémoire, plus la RAM sera soumise à une charge qui deviendra difficile à soutenir, provoquant un effet de goulet d'étranglement.
Face à cette gageure, le site ACM a proposé à Clem Cole, architecte du programme Cluster Ready d'Intel, d'interroger Russell Williams, responsable scientifique de Photoshop, pour évoquer la quinzaine d'années de parallélisme dans Photoshop. Williams a précédemment travaillé chez Apple sur le microkernel de Copland (lire : Il y a 10 ans, la naissance agitée de Mac OS X), quant à Cole, il œuvre à mettre au point des méthodes avancées pour tirer le meilleur parti possible des architectures multiprocesseurs après s'être penché sur le kernel d'Unix.
Les deux spécialistes s'accordent pour dire que le calcul parallèle peut s'avérer particulièrement compliqué. Si le découpage d'une image permet des calculs parallèles relativement simples, c'est notamment parce qu'il ne nécessite pas de synchronisation des résultats. En effet, certaines opérations dépendant du résultat d'autres opérations, il faut prévoir tout un système de gestion des tâches, ce que Grand Central Dispatch prend désormais en charge sur Mac OS X.
Un bug joue à cache-cache pendant 10 ans
Une démonstration éloquente de la difficulté de cette tâche est donnée par Russell Williams : alors que l'équipe avait mis en parallèle diverses tâches simples (suivi du curseur, accès disques…), elle s'est frottée à un bug particulièrement récalcitrant : il aura fallu 10 ans à l'équipe pour parvenir à l'isoler et l'éradiquer. En effet, à l'inverse du code linéaire où il est facile de figer l'état du programme pour voir où le bât blesse, les calculs parallèles rendaient cette inspection impossible. Ces fonctions parallèles ont donc dû être désactivées durant tout ce temps. Jusqu'à ce qu'un ingénieur se rende compte, dix ans plus tard, que le problème venait de la différence entre Mac OS et Windows pour la commande de positionnement de l'index dans un fichier (un seul appel sur Mac et deux sur Windows), qui n'avait pas été correctement prise en compte lors de l'écriture du code.
Un tel problème serait plus simple à éradiquer aujourd'hui, avec l'évolution du C++ et des compilateurs notamment, qui prennent mieux en compte les problématiques liées au calcul parallèle, mais l'exemple illustre bien la difficulté induite par la segmentation des tâches : imaginez ce que ça peut donner s'il est question de passer 95 % du code en calcul parallèle pour atteindre le rendement maximum du graphique ci-dessus… Toujours est-il que l'équipe d'Adobe a dû essuyer les plâtres au fil des ans, se trouvant en première ligne pour découvrir ces problématiques et inventer une méthodologie.
Williams donne une autre illustration de ces problèmes : il est possible de piloter Photoshop pour des tâches répétitives par exemple à l'aide de JavaScript. Si les tâches répétitives se prêtent fort bien au calcul parallèle, les développeurs de Photoshop ne maitrisent absolument pas la structure des scripts réalisés par les utilisateurs finaux. Qui plus est, dans la plupart des cas les langages scripts sont éminemment linéaires de par nature. Pour mettre en parallèle ces opérations, il faudrait donc non seulement le faire de manière dynamique, mais qui plus est sur du code interprété, et donc non-compilé : un vrai casse-tête!

Quel recours pour l'avenir ?
La loi d'Amdahl est au cœur des préoccupations, puisqu'elle rationalise le rendement qu'on peut espérer d'une mise en parallèle des calculs : il faut prendre en considération d'une part l'accélération qu'on peut espérer d'une telle modification, mais également la quantité de travail nécessaire pour y parvenir. Williams se veut toutefois optimiste : les développeurs ont connu une crise similaire à la fin des années 70, alors qu'on s'inquiétait de la complexité des programmes, devenue ingérable pour le commun des mortels. C'est par touches successives que la situation s'est améliorée, avec des progrès structurels au sein des langages de programmation, comme par exemple la programmation orientée objet, ou encore de meilleures performances des compilateurs. Et de fait, le responsable d'Adobe a pu constater des améliorations de cet ordre pour le calcul parallèle dans les outils qu'il utilise au fil du temps, par exemple OpenGL ou OpenCL, permettant un niveau d'abstraction supérieur. Il demeure néanmoins difficile de débugger des programmes "multithread", plus encore lorsqu'on s'adresse à plus d'une plateforme matérielle, mais des outils tels que les TBB (Threading Building Blocks) permettent des avancées.
C'est par l'automatisation du processus que viendra le salut… du moins temporairement. Car malgré l'utilisation de bibliothèques parallèles, comme la transposition d'une image en fréquences, permettant ensuite l'utilisation de la transformée de Fourier rapide (une fonction très véloce de traitement du signal numérique) qu'on peut ensuite faire traiter par le GPU, le passage de bibliothèque en bibliothèque, le découpage forcené des algorithmes finit toujours par se heurter à la loi d'Amdhal, qui s'apparente de plus en plus à un mur infranchissable. Chaque interstice entre chaque étape provoque une perte de rendement, qui aboutit à un plafond quel que soit le nombre de processeurs qu'on ajoute et aussi optimisé que le programme puisse être. Si le passage à deux ou quatre processeurs a bien profité à Photoshop, la transition de huit à seize risque bien de passer inaperçue (lire Photoshop CS5 : plus de cœurs, moins de performances).
Ce constat étant posé, il faut réfléchir à de nouvelles architectures, tant matérielles que logicielles. Intel réfléchit notamment à des plateformes qui s'apparentent à des mini-clusters, en segmentant la mémoire vive pour en dédier chaque partie à un cœur, permettant ainsi d'éviter la saturation des entrées/sorties, ce qui équivaudrait en somme à plusieurs ordinateurs dans l'ordinateur. De son côté, Williams se montre peu intéressé par ces pistes, comme Larrabee (lire Larrabee : c'est où, dites ?), qui ne résolvent que des problèmes spécifiques alors que Photoshop est un logiciel dédié à un marché de masse : avec de tels investissements, hors de question de se limiter à un marché matériel encore hypothétique.
Adobe considère d'ailleurs que l'architecture actuelle continuera de représenter l'essentiel du marché, et compte continuer à s'investir dessus. Partant de là, la voie de recours passera par les processeurs graphiques, et des bibliothèques comme OpenCL, OpenGL et Pixel Bender. En tout état de cause, Williams ne se voit pas tirer parti de nouvelles architectures matérielles sans s'appuyer sur l'interface des systèmes d'exploitation. Ce qui revient à ce que les bibliothèques susnommées se chargent de la transition d'elles-mêmes, sans que les applications n'en soient particulièrement affectées.
La conversation à bâtons rompus entre les deux ingénieurs, aussi absconse qu'elle puisse être, n'en révèle pas moins l'inéluctable réalité : la multiplication des processeurs a permis de gagner un peu de temps avant d'arriver à bout du potentiel du silicium. La réduction de la gravure des processeurs se rapproche à chaque génération un peu plus de la taille de l'atome. Il faudra tôt ou tard changer de paradigme, et pour l'heure l'alternative est loin d'être prête. D'ici là, il faudra donc optimiser à tout crin pour que Photoshop continue à accomplir les tâches en moins de temps qu'il ne faut pour dire "dotriaconta-core".
Avec l'avènement des machines multiprocesseurs, on parle de plus en plus de calcul parallèle : le découpage d'une tâche en plusieurs afin de les exécuter simultanément sur plusieurs processeurs, pour tirer le meilleur parti du matériel.
Si Snow Leopard a mis l'exécution de code en parallèle sur le devant de la scène, avec Grand Central Dispatch et OpenCL, cette technique est pourtant assez ancienne. Elle était particulièrement mise à profit sur les serveurs (chaque tâche étant lancée par un client distinct, la mise en parallèle du code était relativement aisée). Cette architecture s'est retrouvée au sein de l'ordinateur de Monsieur Tout-le-Monde lorsque les fabricants de processeurs sont arrivés au bout de la course au mégahertz : l'augmentation de la cadence des processeurs devenait trop coûteuse et consommatrice d'énergie pour continuer à se justifier.
Mais dans le monde Mac, les machines multiprocesseurs remontent bien avant l'arrivée des processeurs Intel dans nos machines.
En 1995, Apple lancera le Power Macintosh 9500 dont un modèle inclut deux processeurs PowerPC cadencés à 180 MHz, succédé par le Power Macintosh 9600 équipé de deux processeurs à 200 MHz. En 1997, alors qu'Apple avait signé des accords de licence permettant à des constructeurs de fabriquer et vendre des machines compatibles avec Mac OS 8, la société Daystar avait mis sur le marché le Genesis MP, un "monstre" de puissance qui dépassait tout ce qui se faisait de mieux en Mac, à l'aide de quatre processeurs PowerPC 604e cadencés à 225 MHz. Plusieurs configurations de Power Mac G4 et G5 proposeront deux processeurs, le Power Mac G5 sera même équipé en bi-processeurs bi-cœurs en 2006.
Mais si les logiciels ont pu bénéficier de l'augmentation de la fréquence d'horloge des processeurs de manière automatique, sans avoir à être modifiés ou recompilés, les machines multiprocesseurs ne pouvaient être pleinement mises à profit qu'en modifiant les applications spécifiquement. Et en 1995, il n'y avait pas l'ombre d'un Mac OS X en vue, sans même parler de Grand Central Dispatch. Les développeurs étaient donc livrés à eux-mêmes pour tirer parti de ces monstres de puissance.
Un processeur surnuméraire qui ne fait qu'acte de présence
En conséquence, à l'époque bien peu nombreuses sont les applications qui ont été réécrites pour exploiter plus d'un processeur à la fois. Mais s'il est une application, entre toutes, qui peut gagner beaucoup à cette conversion, c'est bien Photoshop, avec ses calculs gourmands en puissance, d'autant plus que le calcul graphique se prête particulièrement bien au calcul parallèle. En effet, à son niveau le plus simple il suffit de diviser l'image sur laquelle on applique un filtre pour en distribuer chaque morceau à traiter par un processeur. Le logiciel à lui seul justifie l'achat de ces machines hors de prix : c'est d'ailleurs une chance, car peu d'autres applications exploitaient à l'époque plus d'un processeur. Photoshop est en conséquence un vétéran du calcul parallèle.
Mais à l'heure où les configurations octo-core, voire hexadéca-core (!) poignent à l'horizon, de nouveaux défis se profilent pour le logiciel d'édition graphique. Car ça n'est pas le tout de convertir certaines parties du code pour les adapter au calcul parallèle : à mesure de l'augmentation du nombre de processeurs, il faut proportionnellement augmenter le pourcentage de calcul parallèle pour continuer à en tirer des bénéfices sensibles. C'est un des enseignements de la loi d'Amdahl, du nom de l'ingénieur d'IBM qui l'a édictée.
Le plafond d'Amdahl
Et précisément, un code rendu parallèle à 50 % ne présentera plus d'accélération sensible entre 8 et 16 processeurs, comme établi sur le schéma ci-dessous.
Pour continuer à sentir la moindre accélération à chaque multiplication de processeurs, il faut donc convertir au parallélisme une partie de plus en plus importante du code, faute de quoi cette multiplication se fait en pure perte. Pour compliquer encore les choses, la multiplication des processeurs peut provoquer quelques congestions au niveau de l'accès à la mémoire vive, qui est partagée avec chacun d'entre eux : plus il y a de processeurs qui provoquent des lectures et écritures en mémoire, plus la RAM sera soumise à une charge qui deviendra difficile à soutenir, provoquant un effet de goulet d'étranglement.
Face à cette gageure, le site ACM a proposé à Clem Cole, architecte du programme Cluster Ready d'Intel, d'interroger Russell Williams, responsable scientifique de Photoshop, pour évoquer la quinzaine d'années de parallélisme dans Photoshop. Williams a précédemment travaillé chez Apple sur le microkernel de Copland (lire : Il y a 10 ans, la naissance agitée de Mac OS X), quant à Cole, il œuvre à mettre au point des méthodes avancées pour tirer le meilleur parti possible des architectures multiprocesseurs après s'être penché sur le kernel d'Unix.
Les deux spécialistes s'accordent pour dire que le calcul parallèle peut s'avérer particulièrement compliqué. Si le découpage d'une image permet des calculs parallèles relativement simples, c'est notamment parce qu'il ne nécessite pas de synchronisation des résultats. En effet, certaines opérations dépendant du résultat d'autres opérations, il faut prévoir tout un système de gestion des tâches, ce que Grand Central Dispatch prend désormais en charge sur Mac OS X.
Un bug joue à cache-cache pendant 10 ans
Une démonstration éloquente de la difficulté de cette tâche est donnée par Russell Williams : alors que l'équipe avait mis en parallèle diverses tâches simples (suivi du curseur, accès disques…), elle s'est frottée à un bug particulièrement récalcitrant : il aura fallu 10 ans à l'équipe pour parvenir à l'isoler et l'éradiquer. En effet, à l'inverse du code linéaire où il est facile de figer l'état du programme pour voir où le bât blesse, les calculs parallèles rendaient cette inspection impossible. Ces fonctions parallèles ont donc dû être désactivées durant tout ce temps. Jusqu'à ce qu'un ingénieur se rende compte, dix ans plus tard, que le problème venait de la différence entre Mac OS et Windows pour la commande de positionnement de l'index dans un fichier (un seul appel sur Mac et deux sur Windows), qui n'avait pas été correctement prise en compte lors de l'écriture du code.
Un tel problème serait plus simple à éradiquer aujourd'hui, avec l'évolution du C++ et des compilateurs notamment, qui prennent mieux en compte les problématiques liées au calcul parallèle, mais l'exemple illustre bien la difficulté induite par la segmentation des tâches : imaginez ce que ça peut donner s'il est question de passer 95 % du code en calcul parallèle pour atteindre le rendement maximum du graphique ci-dessus… Toujours est-il que l'équipe d'Adobe a dû essuyer les plâtres au fil des ans, se trouvant en première ligne pour découvrir ces problématiques et inventer une méthodologie.
Williams donne une autre illustration de ces problèmes : il est possible de piloter Photoshop pour des tâches répétitives par exemple à l'aide de JavaScript. Si les tâches répétitives se prêtent fort bien au calcul parallèle, les développeurs de Photoshop ne maitrisent absolument pas la structure des scripts réalisés par les utilisateurs finaux. Qui plus est, dans la plupart des cas les langages scripts sont éminemment linéaires de par nature. Pour mettre en parallèle ces opérations, il faudrait donc non seulement le faire de manière dynamique, mais qui plus est sur du code interprété, et donc non-compilé : un vrai casse-tête!
Quel recours pour l'avenir ?
La loi d'Amdahl est au cœur des préoccupations, puisqu'elle rationalise le rendement qu'on peut espérer d'une mise en parallèle des calculs : il faut prendre en considération d'une part l'accélération qu'on peut espérer d'une telle modification, mais également la quantité de travail nécessaire pour y parvenir. Williams se veut toutefois optimiste : les développeurs ont connu une crise similaire à la fin des années 70, alors qu'on s'inquiétait de la complexité des programmes, devenue ingérable pour le commun des mortels. C'est par touches successives que la situation s'est améliorée, avec des progrès structurels au sein des langages de programmation, comme par exemple la programmation orientée objet, ou encore de meilleures performances des compilateurs. Et de fait, le responsable d'Adobe a pu constater des améliorations de cet ordre pour le calcul parallèle dans les outils qu'il utilise au fil du temps, par exemple OpenGL ou OpenCL, permettant un niveau d'abstraction supérieur. Il demeure néanmoins difficile de débugger des programmes "multithread", plus encore lorsqu'on s'adresse à plus d'une plateforme matérielle, mais des outils tels que les TBB (Threading Building Blocks) permettent des avancées.
C'est par l'automatisation du processus que viendra le salut… du moins temporairement. Car malgré l'utilisation de bibliothèques parallèles, comme la transposition d'une image en fréquences, permettant ensuite l'utilisation de la transformée de Fourier rapide (une fonction très véloce de traitement du signal numérique) qu'on peut ensuite faire traiter par le GPU, le passage de bibliothèque en bibliothèque, le découpage forcené des algorithmes finit toujours par se heurter à la loi d'Amdhal, qui s'apparente de plus en plus à un mur infranchissable. Chaque interstice entre chaque étape provoque une perte de rendement, qui aboutit à un plafond quel que soit le nombre de processeurs qu'on ajoute et aussi optimisé que le programme puisse être. Si le passage à deux ou quatre processeurs a bien profité à Photoshop, la transition de huit à seize risque bien de passer inaperçue (lire Photoshop CS5 : plus de cœurs, moins de performances).
Ce constat étant posé, il faut réfléchir à de nouvelles architectures, tant matérielles que logicielles. Intel réfléchit notamment à des plateformes qui s'apparentent à des mini-clusters, en segmentant la mémoire vive pour en dédier chaque partie à un cœur, permettant ainsi d'éviter la saturation des entrées/sorties, ce qui équivaudrait en somme à plusieurs ordinateurs dans l'ordinateur. De son côté, Williams se montre peu intéressé par ces pistes, comme Larrabee (lire Larrabee : c'est où, dites ?), qui ne résolvent que des problèmes spécifiques alors que Photoshop est un logiciel dédié à un marché de masse : avec de tels investissements, hors de question de se limiter à un marché matériel encore hypothétique.
Adobe considère d'ailleurs que l'architecture actuelle continuera de représenter l'essentiel du marché, et compte continuer à s'investir dessus. Partant de là, la voie de recours passera par les processeurs graphiques, et des bibliothèques comme OpenCL, OpenGL et Pixel Bender. En tout état de cause, Williams ne se voit pas tirer parti de nouvelles architectures matérielles sans s'appuyer sur l'interface des systèmes d'exploitation. Ce qui revient à ce que les bibliothèques susnommées se chargent de la transition d'elles-mêmes, sans que les applications n'en soient particulièrement affectées.
La conversation à bâtons rompus entre les deux ingénieurs, aussi absconse qu'elle puisse être, n'en révèle pas moins l'inéluctable réalité : la multiplication des processeurs a permis de gagner un peu de temps avant d'arriver à bout du potentiel du silicium. La réduction de la gravure des processeurs se rapproche à chaque génération un peu plus de la taille de l'atome. Il faudra tôt ou tard changer de paradigme, et pour l'heure l'alternative est loin d'être prête. D'ici là, il faudra donc optimiser à tout crin pour que Photoshop continue à accomplir les tâches en moins de temps qu'il ne faut pour dire "dotriaconta-core".