Voilà un signe qu'OpenCL est en passe d'obtenir le statut de standard qu'Apple a clairement ambitionné pour lui en offrant sa technologie de GPU computing au Khronos Group : un groupe de chercheurs l'a mis à profit pour un modèle physique reproduisant les ondes gravitationnelles générées par des objets stellaires (tels qu'une étoile de la taille de notre soleil) en orbite déclinante autour de trous noirs supermassifs. Ces derniers (que la communauté scientifique dénomme EMRI : Extreme Mass-Ratio Inspirals, d'une masse souvent supérieure à un million de fois celle du soleil) se trouvent au centre de la plupart des galaxies, et dévorent avec appétit étoiles et autres trous noirs.
Un tel modèle est assez complexe à mettre en œuvre et nécessite une grande puissance de calcul, mais se prête particulièrement bien au calcul parallèle. Une tâche toute trouvée pour OpenCL qui se voue précisément à faire effectuer du calcul parallèle aux processeurs graphiques. Les chercheurs ont ainsi pu faire tourner le même code sur différentes configurations, grâce à la vocation universaliste d'OpenCL. Le résultat est sans appel : sur des processeurs de compétition (Cell Broadband Engine et Tesla), les performances sont plus de 25 fois supérieures à celles observées avec un CPU standard.
Les chercheurs notent que les performances sous OpenCL sont similaires à celles observées avec CUDA d'une part pour le processeur Tesla, et avec le Cell SDK pour le processeur du même nom, avec toutefois l'avantage significatif sur ces derniers de ne pas avoir à réécrire le code puisqu'il fonctionne sur toute architecture qui dispose d'un driver pour OpenCL.
Les machines utilisées pour ces tests sont un Blade System QS22 d'IBM doté de 2 processeurs Cell BE cadencés à 3,2 GHz et de 16 Go de RAM d'une part, et de l'autre d'une machine équipée d'un processeur AMD Phenom quad-core à 2,5 GHz et de 4 Go de RAM qui intégrait une carte NVIDIA C1060 Tesla CUDA. Les deux machines fonctionnaient sur Fedora Linux et exploitaient les bibliothèques OpenCL et les compilateurs livrés par les constructeurs.
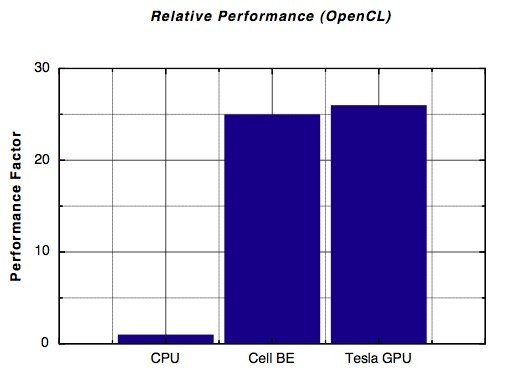
Un tel modèle est assez complexe à mettre en œuvre et nécessite une grande puissance de calcul, mais se prête particulièrement bien au calcul parallèle. Une tâche toute trouvée pour OpenCL qui se voue précisément à faire effectuer du calcul parallèle aux processeurs graphiques. Les chercheurs ont ainsi pu faire tourner le même code sur différentes configurations, grâce à la vocation universaliste d'OpenCL. Le résultat est sans appel : sur des processeurs de compétition (Cell Broadband Engine et Tesla), les performances sont plus de 25 fois supérieures à celles observées avec un CPU standard.
Les chercheurs notent que les performances sous OpenCL sont similaires à celles observées avec CUDA d'une part pour le processeur Tesla, et avec le Cell SDK pour le processeur du même nom, avec toutefois l'avantage significatif sur ces derniers de ne pas avoir à réécrire le code puisqu'il fonctionne sur toute architecture qui dispose d'un driver pour OpenCL.
Les machines utilisées pour ces tests sont un Blade System QS22 d'IBM doté de 2 processeurs Cell BE cadencés à 3,2 GHz et de 16 Go de RAM d'une part, et de l'autre d'une machine équipée d'un processeur AMD Phenom quad-core à 2,5 GHz et de 4 Go de RAM qui intégrait une carte NVIDIA C1060 Tesla CUDA. Les deux machines fonctionnaient sur Fedora Linux et exploitaient les bibliothèques OpenCL et les compilateurs livrés par les constructeurs.