





Bien qu’elle se soit érigée en championne du chiffrement, Apple n’a jamais été opposée à la collecte de données personnelles. Au contraire : si elle s’est opposée aux demandes du FBI, c’est bien pour protéger les données qu’elle avait collectées. Plus que jamais, la firme de Cupertino amasse une mine d’informations sur vos usages, pour nourrir les algorithmes des suggestions Spotlight ou de la reconnaissance vocale. Mais en adoptant des mécanismes de privacité différentielle, Apple veut concilier le traitement des données à grande échelle avec la protection de l’intimité personnelle.

« Nous pensons que les nouveautés et la vie privée devraient aller de pair », explique Craig Federighi :
La privacité différentielle est un sujet de recherche dans le domaine de la statistique et de l’analyse de données, qui exploite le hachage, l’échantillonnage et la génération de bruit pour permettre [un] apprentissage participatif qui préserve parfaitement l’intimité des données individuelles. Apple a réalisé un travail super important dans ce domaine afin de permettre le déploiement à grand échelle de la privacité différentielle.
Vous n’avez pas tout compris ? Reprenons les explications. Imaginons que vous travaillez dans l’équipe chargée des suggestions Spotlight : pour affiner les suggestions d’applications ou d’actualité, vous avez besoin de savoir quelles applications et quelles actualités ont été sélectionnées par les utilisateurs selon le moment de la journée et le lieu. Mais vous devez le faire de telle manière qu’il soit impossible de savoir quelles applications ou quelles actualités ont été sélectionnées par un utilisateur en particulier.
Parce que vous ne travaillez pas vraiment dans l’équipe chargée des suggestions Spotlight, vous vous dites qu’il suffit d’anonymiser les données envoyées. Sauf qu’il serait possible d’utiliser les informations de localisation pour croiser certaines informations avec d’autres données localisées, comme celles que l’on peut trouver sur les réseaux sociaux, et in fine de retrouver un utilisateur. L’anonymisation ne suffit pas : Netflix l’a appris à ses dépens.
Vous faites confiance à Apple ? Grand bien vous en fasse, mais les données collectées sur votre iPhone peuvent être stockées chez Google ou Amazon, et traitées par de petites sociétés spécialisées dont vous n’avez jamais entendu parler. Pas besoin d’évoquer la perspective d’un piratage de grande ampleur pour comprendre comment de telles données peuvent échapper au contrôle de l’utilisateur.
D’où l’utilité de la privacité différentielle, qui sort doucement des universités, où elle est étudiée depuis une quinzaine d’années. Le gouvernement américain exploite ses principes pour extraire des recensements les données sur les déplacements, qui peuvent instruire les politiques publiques en matière d’infrastructures.
Google et Microsoft s’en servent pour récupérer certains mots-clefs de leurs moteurs de recherche, afin de suivre l’évolution d’une épidémie de grippe par exemple. Mais le déploiement d’Apple sera sans doute le plus important jamais réalisé dans le domaine, et surtout le plus systématique : il concernera de nombreux aspects de l’utilisation de centaines de millions d’appareils.
Lorsque l’utilisateur cliquera sur une suggestion Spotlight, son appareil n’enverra pas directement toutes les informations associées à cette action. Apple n’ayant pas fourni les détails de son implémentation, et par souci de simplification, on peut imaginer qu’il tirera un chiffre au hasard : si tel ou tel chiffre sort, les données réelles seront chiffrées et hachées avant d’être envoyées ; sinon, un jeu de données aléatoire sera envoyé après avoir été chiffré et haché.
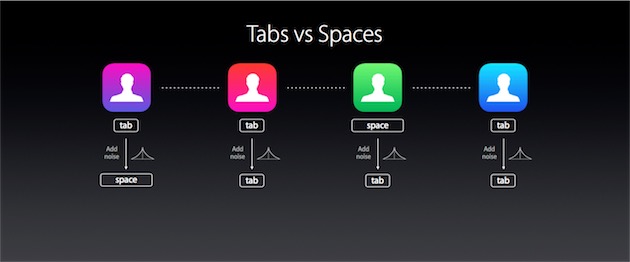
Le serveur connaît la probabilité que tel ou tel chiffre ait été tiré, et donc la quantité de données qui relèvent du bruit plutôt que du signal, et sait aussi comment les décoder. Mais il ne sait pas quelles données sont exactes et quelles données sont aléatoires : à l’échelle d’un individu ou d’un petit groupe, le jeu de données n’est pas fiable, et la vie privée de chacun est préservée. À l’échelle de plusieurs centaines de millions de personnes toutefois, il permet de mener un traitement massif et plutôt pertinent.
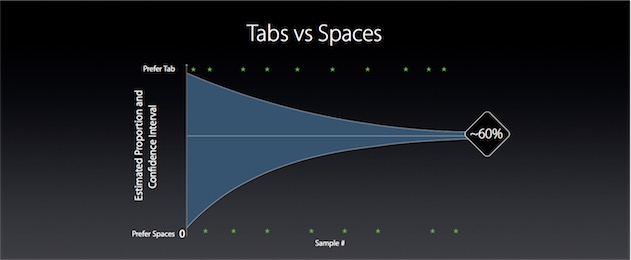
Ou du moins, il le permet si le bruit n’est pas trop important : plus il l’est, plus il est difficile de dégager le signal original ; mais moins il l’est, plus il est facile de retrouver les données originales et d’en faire « fuiter » des informations privées. Toute l’efficacité du système repose donc sur la définition de la marge d’erreur : Apple se contente d’un intervalle de confiance de 60 %, un chiffre qui ne serait pas suffisant pour des recherches démographiques ou épidémiologiques, mais qui l’est sans doute pour des suggestions de liens et d’applications.
La firme de Cupertino prend d’autres précautions contre les « pièges » statistiques. Elle limite ainsi le nombre de données envoyées par chaque utilisateur : si un utilisateur contribue beaucoup plus que les autres à un jeu de données, ses informations privées sont plus vulnérables. Elle supprime aussi toutes les données de manière périodique, ne conservant que les résultats.
L’ensemble de ce mécanisme — mathématiquement et statistiquement beaucoup plus complexe que ne le sont ces explications — permet théoriquement de concilier intimité et collecte. Et en pratique ? Il est difficile de le dire sans jeter un coup d’œil sous le capot. Aaron Roth l’a bien fait, mais le co-auteur du livre de référence sur la privacité différentielle se contente d’applaudir l’initiative d’Apple, sans la juger. Ce qui n’est déjà pas si mal.





