Apple continue de distiller ses efforts dans le domaine de l’IA à travers différents papiers de recherche. Après Ferret ou MGIE, l’entreprise a récemment levé le voile sur MM1, un nouveau modèle multimodal pouvant travailler avec du texte et de l’image.

MM1 peut répondre à des demandes naturelles pouvant porter sur des photos. Le papier de recherche donne un exemple où on lui montre un cliché représentant une table sur laquelle sont posées plusieurs bouteilles de bière avant de lui montrer un menu de restaurant. On lui demande ensuite combien il faut s’attendre à payer pour tout cela, ce à quoi le modèle répond correctement. On peut aussi voir MM1 décrire l’ambiance d’une image de manière détaillée, ou effectuer différentes déductions logiques. Le modèle est également sollicité pour aider à utiliser une machine à café, et se débrouille bien pour répondre à plusieurs requêtes à la suite.
Ce type de modèle est similaire sur certains points au Llama de Meta ou au Gemini de Google. Il peut servir à alimenter un chatbot général ou plus spécifique, par exemple en effectuant des actions. On peut imaginer que la nouveauté finira par trouver sa place dans l’écosystème Apple, comme pour décrire des photos ou des documents. Ce type de technologie ouvre notamment de nombreuses portes dans le domaine de l’accessibilité.
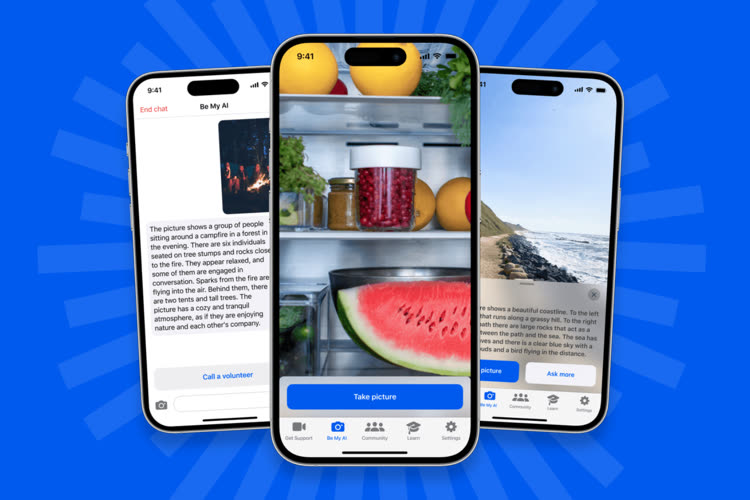
Be My AI : quand GPT-4 décrit fidèlement l'environnement des personnes aveugles

Le modèle est composé d’une famille de différentes tailles, globalement assez petit si l’on se fie à leur nombre des paramètres. Les chercheurs expliquent obtenir tout de même de bons résultats grâce à un gros travail d’optimisation. Le but est sans doute de le faire tourner en local sans passer par le nuage, ce qui est un bon point niveau confidentialité. Cela demande cependant pas mal de puissance sous le capot : il semblerait qu’Apple envisage des déclinaisons mettant le paquet sur l’IA pour ses prochaines puces de smartphone.
Source :